by Oshrat Nir on Oct 6, 2021

Kubernetes is a fast-moving open-source project. The guiding principle being: release early and release often. This philosophy is a key reason Kubernetes matured as quickly as it did. As a result, the basic formula for Kubernetes releases is to expect a big release every three to four months. The support window for each release is one year.
This puts pressure on providers of the Kubernetes distributions/platforms to keep up with this cadence. Keeping up to date helps users of Kubernetes to use the new features that are rolling out. In addition, it keeps organizations safe by implementing CVE patches earlier rather than later.
Are you up to date?
The above thread on Twitter gave an eye-opening overview of the upgrade debt that exists in the market today. While the thread presents data about multiple providers. Below you can find representative market leaders — EKS and OpenShift.


These graphics put the problem of keeping up with new versions of Kubernetes front and center. The fact is that technical debt is getting accrued all over the market, across different Kubernetes distributions.
Intel categorized technical debt into 3 types:

(source: adapted from Intel)
Lagging on upgrading Kubernetes falls into the category of technical debt that is 'Rotten'. Flinching away from the perceived (or actual) pain of upgrading, will not resolve it. On the contrary, putting upgrades off has the potential to blow up.
We’ve established that upgrade debt is bad for business and keeping up with newer versions brings more security, reliability, and new functionality. So, why are upgrades even a problem?
Why aren’t you up to date?
In many IT circles upgrades are notoriously risky. As such, many organizations adopt a 'deferred maintenance' strategy, or in other words 'if it ain’t broke don’t fix it'. We think of this as an opportunity/cost exercise.
Would things be more broken in a legacy state or the latest and greatest?
The answer, especially in the fast-paced cloud-native world, will almost always be legacy. The only difference between new and old is that the broken things are known and users have gotten comfortable with them. In some cases, there's a growing mass of workarounds and point solutions that were implemented over time. This is costly to create, difficult to maintain, and hard to rely on. Yet, it is also difficult to part with.
There is also often that one compelling event that creates the need to jump, not one, but many versions. An example of this is a CVE that very publicly caused problems and raised awareness of the upgrade debt. As a provider of managed Kubernetes, we realized that our customers need help controlling their upgrade debt.
The tweet above, from our CTO Timo, reflects that we provided a patch within 24 hours to keep our customers safe. However, our customers were still having a hard time keeping up, resulting in technical debt.
The obstacles in our way:
- We have a release cadence that our customers have a hard time following since customer internal upgrade processes are slower than our continuous delivery.
- Customers don’t trust the upgrade process. As mentioned earlier, upgrades are perceived as risky.
- We let the customer decide when to upgrade a cluster.
- We operate a variety of cluster versions, which makes providing the best support tricky for us.
Our goal became:
Have customers on the latest patch/minor release of one of the two major Giant Swarm releases maintained.
A short explanation of Giant Swarm releases structure:
- Patch: A bug fix/patch on any of the components in the platform or managed apps (CVE, bug, or regression in functionality). It should be deployable at any time, containing a single change and not adding any breaking change (on infra or configuration terms). It should be easy to revert or roll back.
- Minor: A minor change on any of the components in the platform or managed apps. No breaking change. No changes in underlying layers. Only addition of on-demand, non-default features.
- Major: Any major change of the components in the platform or managed apps (exception: Kubernetes minors are Giant Swarm majors). New features. Big changes in underlying layers (networking, security, etc.). This may also include breaking changes.
We always spin up new nodes rather than patch existing ones due to the immutability concept.
On the upgrade track
For all the reasons mentioned above, we were always intentional about keeping our customers on the latest available version (or two). As our customers grew, we found that they were getting stuck on old versions. This brought about a project in which we gave a lot of focus to engaging with our customers around upgrades and nudging them in the right direction. In short, once it was easier for them we began to see really nice results.
The graph below depicts the problem we faced and when things started turning around.
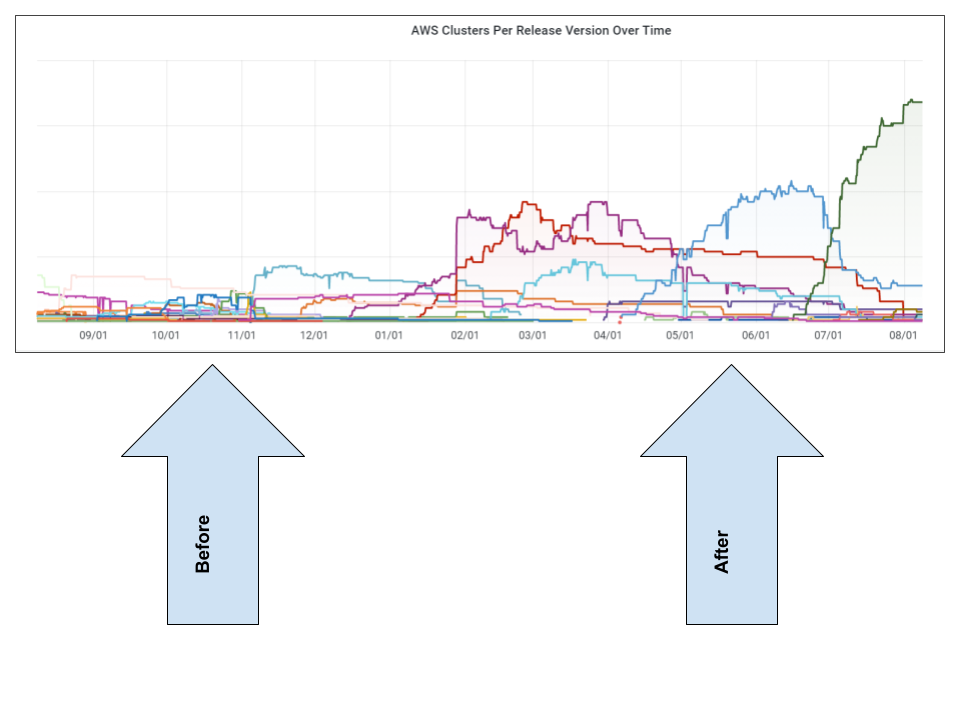
The graph above covers 10 months of work. We worked internally to make upgrades delightful. We worked with customers to prove the value of new versions in addition to proving risk reduction.
The first half — before — of the graph shows the spaghetti that we had. We were running around a dozen versions. Much of this was caused by a broken upgrade path. Paired with the slow pace at which customers were adopting new versions, it spelled disaster.
It was also very frustrating, our customers were asking for features, we were providing them, yet adoption was lagging. Essentially we were rolling out useful features like spot instances and node pools, into a void.
The second half — after — of the graph shows things starting to take shape. Adoption rates of versions were trending higher. In addition, it's very easy to see the lifecycle of a version in the time-lagged peaks. As one version hits its stride and starts going mainstream, the other version starts showing a decline.
A clearer view of the situation after can be seen in the graphic below:
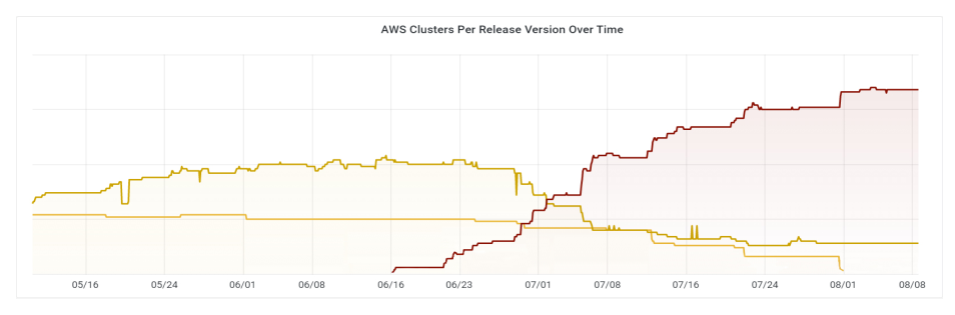
This graph zooms in on the past three months. In it, you can see the clear replacement of versions for the majority of workload clusters. We are trending in the right direction.
That being said, the nearly static line at the bottom of the graphic indicates that our work is not over. We continue to work with our customers to get their workloads on the most up-to-date clusters.
A more qualitative measure of the success of this endeavor can be illustrated by a recent customer interaction. A project manager hadn’t noticed any noise about upgrades for awhile and asked a platform engineer why he had forgotten about them. The reply was that the upgrades scheduled for that morning were already done. No fuss, no problems.
What the future holds
If you have been keeping up with Giant Swarm (if you haven’t, you might want to follow us on Twitter) you may be aware that we are adopting Cluster API (CAPI). This will definitely impact the way we do upgrades. That being said, we won't be abandoning our mission of keeping our customers up to date.
There are a few things we know for sure. Upgrade cadence will be even more affected by upstream than before. Not only will we be following Kubernetes, we will also be following Cluster API. That being said, we’ll be able to invest less in core functionality, since we can rely on upstream. This will allow us to focus more on delightful upgrades (and other value adds) for our customers. CAPI decouples components (even more than we currently do), which will enable us to roll out bug/security fixes only for the affected components. Thus, continuing to reduce the risk of upgrades.
The end goal is for our customers to have more control. Not only will they continue to define the maintenance window. They will also have the freedom to define which clusters will be affected and trigger an automatic update. Upgrades will be granular to the point that the user can indicate control planes and node pools (even single separate node pools) to be upgraded independently. You can learn more about how in this Request for Comments (RFC) we recently published.
If something goes wrong, we are still a call away, though typically our monitoring setup will catch problematic upgrades, even before customers notice.
Contact us if you would like Giant Swarm to ensure you don’t get stuck with those risky, outdated versions.

The Graphic Guide to Evolving Cloud-native Deployments
This blog post was inspired by a talk given by Timo Derstappen, Giant Swarm Co-Founder and CTO.
Giant Swarm’s giant network
‘Reflection meets celebration’ is usually a good way to distill the multiple and often contradictory feelings inspired by a birthday. In other words, …

GitOps with Jenkins X
In this penultimate article in our GitOps series, we're taking a look at another heavyweight solution to the automated continuous deployment quest: Je …