by Anna van Dillen on Jun 3, 2021

Okay, okay, so, here’s a good one:
A CTO walks into the HR (virtual) office and says: “I think we should restructure most of our company, and can you please make sure to have it done within two weeks?“
And joking aside, this is more or less how we started the Cluster API (CAPI) Hive Sprint.
But let’s first start with the problem that we were trying to fix. We at Giant Swarm decided that now is the right time to move large parts of our technology to fit an open standard. We had a working group looking into Cluster API for a while and some teams already started actively implementing things to prepare for the transition. But somehow, everything still seemed to be pretty complex and we had to deal with lots of unknowns, while still thinking about seven distinct teams that would be impacted by the work to be done. This is when two team members suggested to Timo, our CTO, that we streamline the work to avoid any communication and complexity overhead, which was already foreseeable. He liked the idea and thought about what would need to happen. His parameters were:
- All teams from two of our three technical areas should join
- Existing team boundaries should be dissolved
- Newly formed teams should be platform agnostic
- There would be full focus on the transition for one month with all other distractions reduced to the bare minimum
We got together and came up with an approach that was structured enough to overcome all the initial confusion that would naturally arise, while at the same time being flexible enough to accommodate any unforeseen learnings that might lead to a change of course. Here's how we approached it and what we learned along the way.
Full focus
Let’s start with the easiest. We know that creating focus means getting rid of distractions. As we're already doing quarterly Hackathons, we're used to temporarily canceling all meetings and managing our customer requests through a priority funnel. That’s why it didn’t feel too scary to expand that modus operandi from a couple of days to a full month. People initiatives got postponed, sales requests got handled through our management, and all uncritical SIG & WG meetings were paused. Thereby we made sure that people had all the space and time they needed to start peeling off the different layers of Cluster API and iteratively move to a technical solution that would work for all of us.
Alignment
Now that we had everybody's attention, all we had to do was create the space for alignment. As systemic coaches, we believe that all solutions are to be found within the system. This meant we didn’t try to tell people what to do but instead asked the right questions in order to help them have their say. As we are a fully remote company, we got together on Google Meet. For all the online collaboration, we chose the tool Miro as we liked the space and flexibility it offers for a lot of people simultaneously over a prolonged period.
We started by aligning on the goal. Leaning on the ideas of Design Sprints by Jake Knapp from Google, we asked everybody where they thought we would be in 12 to 18 months if we were super optimistic. Then everybody had the chance to read each other's long-term goals and we voted to determine which goals stuck.
Afterward, we put our grumpy hats on and asked everybody to be super pessimistic and to think of all the things that could possibly go wrong. We then voted on which sprint questions or concerns were most risky.
With that input we moved to an 'expert panel' discussion, consisting of the people who had previously looked into CAPI to varying degrees. Everybody else killed their video and we focussed on discussing the most pressing concerns first. If there were specific questions in the room, the relevant people would turn their video back on and join the discussion until there was an answer. That way, we were able to answer some of the questions directly and agree on approaches for others. From the discussions, we distilled the most important overarching themes that would form the basis to distribute the work for the next month. We called those Hives. Around those Hive themes, we self-organized into cross-functional teams (we called those Swarms) and started thinking about the risks, assumptions, issues, and dependencies for each Hive to be able to address those very early on in the process. In a speed-dating format, we finally mixed-and-matched all Swarms with each other to discuss their dependencies and how they wanted to go about them.
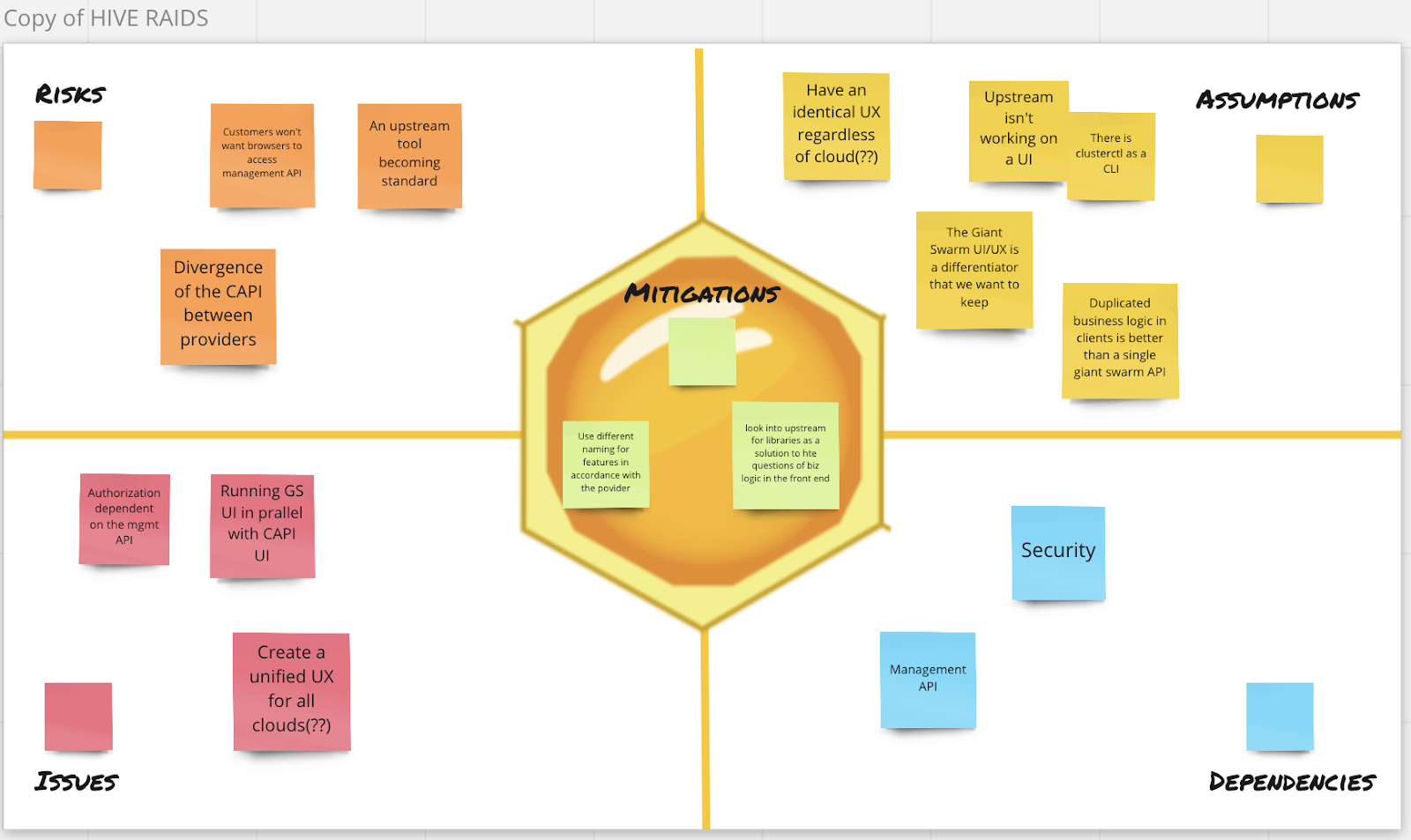
All of this happened on the first day! You can imagine that it was quite a marathon, but we believe that an intense initial time together to get everybody involved and thinking in unison is time well spent.
Team building
Let’s see what we’ve got.
- Creating time and space for people to focus on one thing
- Getting on the same page about what we are setting out to achieve
What remains is a bunch of people who haven’t worked together before and a Hive topic but no clue where to start.
That’s why we started the second day with some Swarm alignment. The freshly formed Swarms got together to discuss individual constraints, like time zones or childcare, communication agreements, like meeting rituals and Slack channels, and roles and responsibilities, like expectations from others and agreements around shared responsibilities, and finally collaboration, like pairing and review processes.
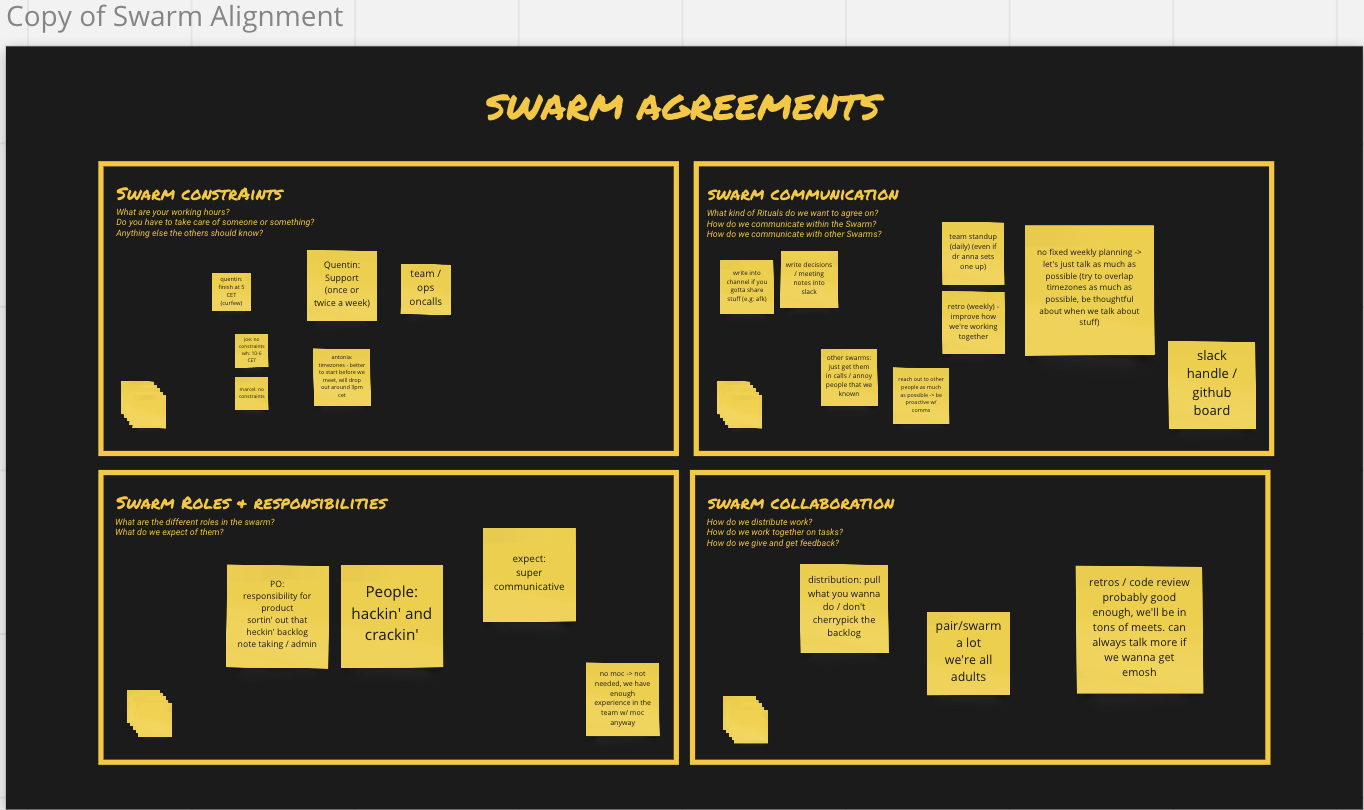
And that’s basically all that was needed to finally start thinking about how to break the work down and actually get working.
From here onwards it was mostly self-organization, to be honest.
We still don’t know if it was because our crew is just plain awesome and so used to self-organizing their work that it seemed like a breeze from the outside — or because it just really is that simple.
The only thing we continuously offered was cross-cutting Hive syncs, where individual people from each Hive got together to update each other on what they were currently working on and discuss how to go about dependencies. Furthermore, all Swarms were doing weekly retrospectives to continuously improve their work and collaboration. We shared those publicly to learn from each other, and also about the Hive Sprint in general for future editions.
Some time halfway through the Sprint, we took a moment to step back and take a look at the bigger picture again. We discussed if the Hives still made sense or if some turned out to be obsolete or even missing. We looked at the composition of the Swarms and shuffled around some people based on their expertise. And we asked ourselves what a cool MVP per Hive could look like, which was ambitious to achieve but still possible within the next two weeks.
Afterward, it was all "bulldoze and cheerlead” until the finish line. I’m stealing this expression from my former colleague Laura, who used it to describe her favorite leadership style: get all the blockers out of the way and cheer loudly from the sidelines!
We ended the Hive Sprint with a closing ceremony open to the entire company. All Hives presented their achievements and we collectively voted on the most impressive achievement. (The respective Swarm members each received a jar of honey, along with a bee sponsorship. 🐝🍯)
Leftovers
Obviously, there were still a bunch of things to do before we could go back to normal. Swarms had to clean up their code and think about how to distribute their work in the future. We had some calls during the first days, but the POs took care of most of the open discussions, and things moved back into the old rhythm quite smoothly. Now Cluster API is tightly woven into the structures of our company with teams working on it on a daily basis. Our content creators are still busy writing about and organizing everything that we have learned along the way, and we are talking to our customers about the next steps. Overall, we are super happy with how things worked out. Most people really enjoyed breaking out of their routines for a bit, and we were also pretty successful in paving the technical path for our future endeavors. However, there is always something to learn to improve ourselves in the future. So here are some of our major learnings to end with.
What we’ve learned
Although we tried our best to create focus time, we had to realize that people's established routines and rhythms were in many cases finely orchestrated around personal and family duties too. With the new and often ad-hoc planning of the Hive events, we made it pretty hard for some people to juggle both work and private life. While most were able to shift stuff around in order to attend group meetings during the first week, it seemed to become less doable during the later weeks. This resulted in group meetings unexpectedly being much smaller than anticipated and context sharing much harder to sustain. However, self-organization quickly opened up other communication channels and we found that providing a framework for everybody was much less needed than we had first thought.
In addition, the obvious things — change can be pretty exhausting and people work differently — became very obvious as we confronted the balancing act between established systems and new approaches. I mean, maybe we shouldn’t have climbed Mount Everest on our first hike, with a huge topic and only four weeks to do it — but it worked.
In our next long sprint, one thing we want to try to improve is how we help new Swarms more on an individual level. Teams developed differently, and therefore our group workshops were less relevant to some than to others. We think that by creating prior templates and enabling more individual facilitation as needed we can definitely get better here.
We also tried to navigate the balancing act between needing alignment and asynchronous communication with honesty and transparency. What worked in the beginning, might not work in the end and we tried to accept that as happily as we accepted what did work. For our next Hive (and yes, it’s already in the pipeline) we’ll aim for more PO involvement and better asynchronous communication. However, overall we’re happy with the process as well as the result and are excited about the possibilities of where our next Hive will take us.

Part 3: Deploying the Application with Helm
An in-depth series on how to easily get centralized logging, better security, performance metrics, and authentication using a Kubernetes-based platfor …

It's Cluster API time — are you ready?
As some of you might have seen, we’ve been working on and talking about Cluster API a lot lately. I felt like now’s a good time to review what Cluster …

How Developer-Focussed Startups can Promote Transparency - Even in Legal
Two of our core principles at Giant Swarm are being developer-focused and striving for transparency.