by Ross Fairbanks on Jun 21, 2018

A lot of us at Giant Swarm were at KubeCon in Copenhagen back in May. As well as being 3 times the size of the previous edition in Berlin the atmosphere felt very different. Far more enterprises were present and it felt like Kubernetes has now gone mainstream.
As strong supporters of Kubernetes, it being the most widely deployed container orchestrator makes us happy. However, this poses the same question that James Governor from RedMonk wrote about Kubernetes won – so now what?
Part of this growth is that there are now a wide range of Cloud Native tools that provide rich functionality to help users develop and operate their applications. We already run many of these CNCF projects such as Prometheus, Helm, and CoreDNS as part of our stack. Rather than install and manage these tools themselves our customers want us to provide them, too.
At Giant Swarm our vision is to offer a wide range of managed services running on top of Kubernetes, as well as managed Kubernetes. These services will help our customers manage their applications, which is what they actually care about. We call this the Managed Cloud Native Stack. We already provide managed services within our clusters. We’ll be launching our first optional services at the end of Q1 2019. This post is to give you a preview of what’s coming.
Managed Kubernetes is still important
We’re expanding our focus to provide a managed Cloud Native Stack but managed Kubernetes will remain an essential part of our product. Not least because all our managed services will be running on Kubernetes. We continue to extend our Kubernetes offering and have recently linked up with Microsoft as Azure Partners. So we now have Azure support to add to AWS and KVM for running on-premise.
Our customers each have their own Giant Swarm Installation. This is an independent control plane that lets them create as many tenant clusters as they require. This gives flexibility as they can have development, staging, and production clusters. Teams new to Kubernetes can have their own clusters and later these workloads can be consolidated onto larger shared clusters to improve resource utilisation and reduce costs. A big benefit is, there are no pet clusters. All these clusters are vanilla Kubernetes running fixed versions. They are also all upgradeable.
This ability to easily create clusters also means we manage 1 to 2 orders of magnitude more clusters than a typical in-house team. When we find a problem it is identified and fixed for all our customers. This means in many cases that our customers never even see a problem because it was fixed for another customer already.
Each tenant cluster is managed 24/7 by our operations team. To do this a key part of our stack is Prometheus which we use for monitoring and alerting. Prometheus will also be in the first set of managed services we provide. It will be easy to install Prometheus and it will also be managed by us 24/7. Using our operational knowledge of running Prometheus in production at scale.
Helm and chart-operator
Helm is a key part of our stack. As its templating support makes it easy to manage the large number of YAML files needed to deploy complex applications on Kubernetes. Helm charts are also the most popular packaging format for Kubernetes. There are alternatives like ksonnet, but Helm is the tool we use at Giant Swarm.
We use automation wherever possible in our stack. A lot of this automation uses the Operator pattern originally proposed by CoreOS. This consists of a CRD (Custom Resource Definition) that extends the Kubernetes API and a custom controller which we develop in Go using our OperatorKit library.
To enable the Managed Cloud Native Stack we’ve developed chart-operator. This automates the deployment of Helm charts in our tenant clusters. We use Quay.io as our registry for container images and also for charts using their Application Registry. This approach lets us do continuous deployment of cluster components including managed services across our entire estate of tenant clusters.
chart-operator comes with support for release channels. As well as providing stable channels for production there can also be alpha and beta channels. This lets users try out new features on development clusters. It also lets us have incubation charts for new tools. This is important because of the pace of development of cloud native tools under the umbrella of the CNCF.
We’re already using chart-operator to manage cluster components like node-exporter and kube-state-metrics that support our Prometheus monitoring. We also use it for the Nginx Ingress Controller which we pre-install in all tenant clusters. With managed services, this will become an optional component but also configurable. For example, customers will be able to install separate public and private Ingress Controllers.
The charts we use are production grade based on our experience of operating these tools. This means they often have features not present in the community Helm charts. The charts are also designed to work with our monitoring stack. So for example, if an Ingress Controller breaks in the middle of the night our operations team will be alerted and resolve the problem.
Service Catalogue
As part of the Managed Cloud Native Stack we’re adding a Service Catalogue to our web UI, API, and gsctl our command line tool. This easily shows which components are running and lets users select which tools from the Cloud Native Stack they wish to install. 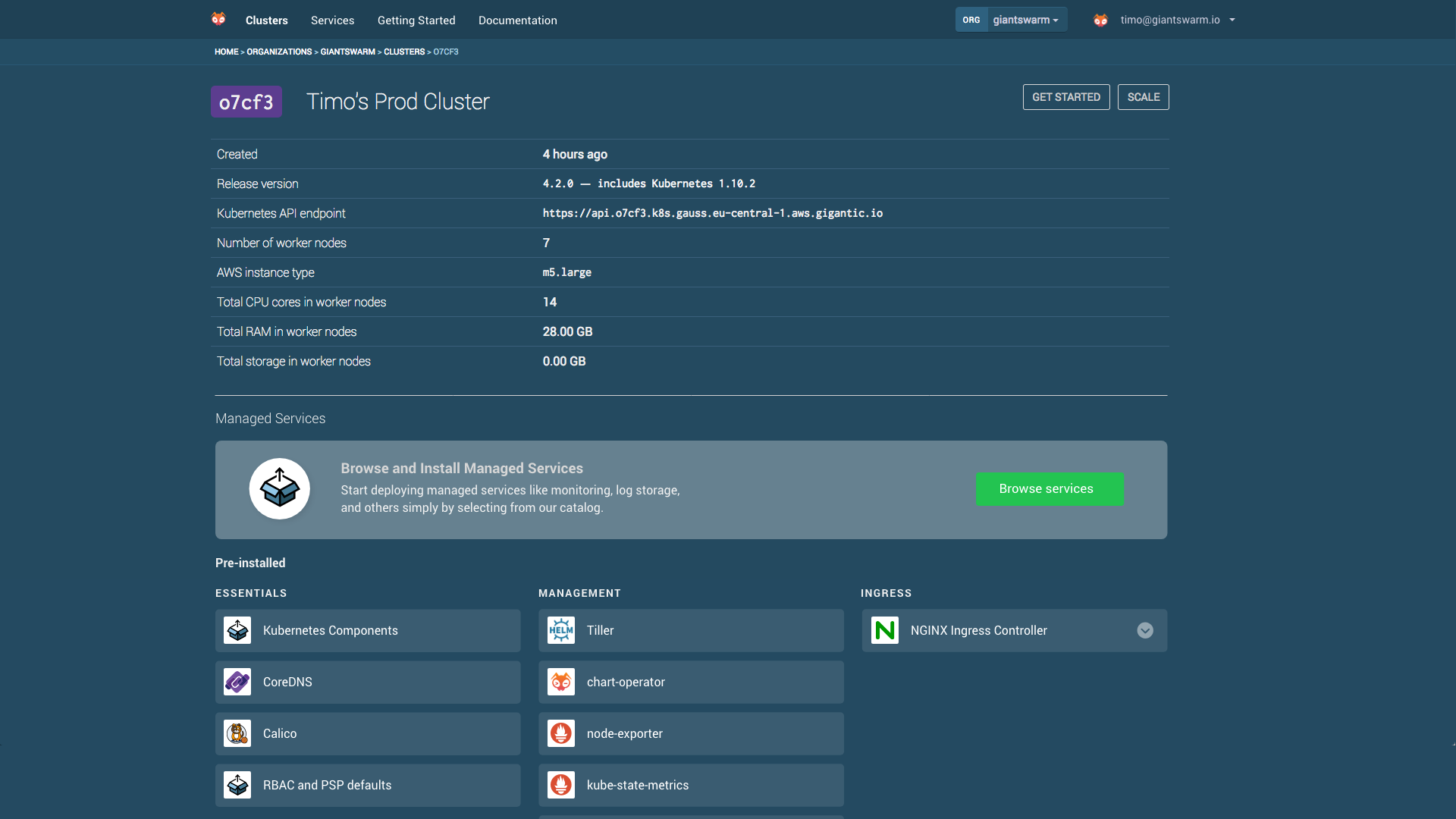
In the screenshot above you can see a typical cluster. The management and ingress components are all being managed by chart-operator. Additional tools can be selected from the service catalogue shown at the beginning of the post. 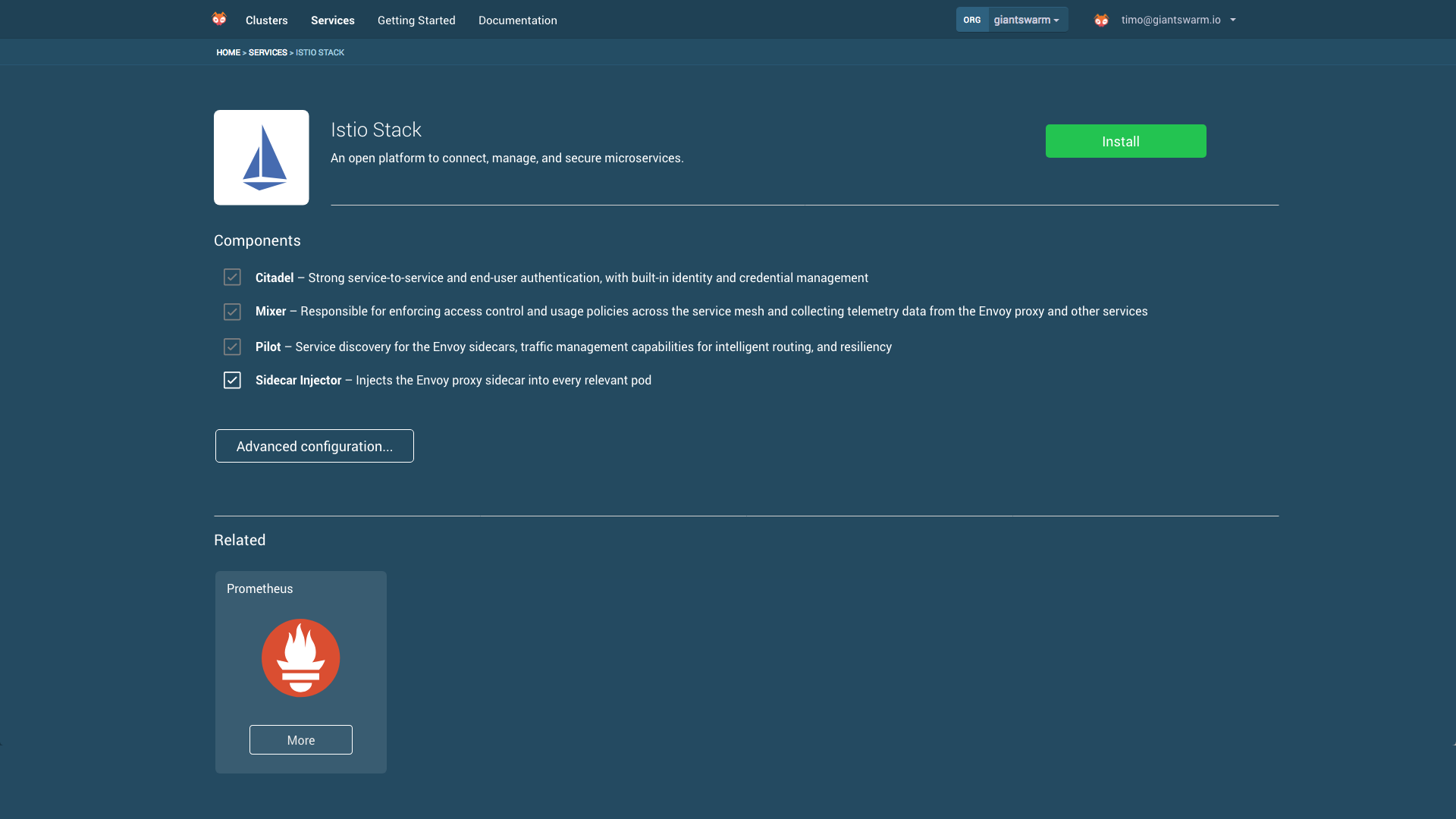
In the screenshot above you can see how components can be configured. In this case for the Istio service mesh, you can decide whether to inject the Istio sidecar pod into your applications.
Conclusion
We think as the Kubernetes and Cloud Native ecosystems continue to evolve, providing a wider set of services is essential. These services will be pre-installed or available later in the clusters we manage and also be managed by us. This helps our customers focus on running their applications and still take advantage of the rich functionality these tools provide. If this matches what you think a Managed Cloud Native Stack should provide, we’d like to hear about your use case. Request your free trial of the Giant Swarm Infrastructure here.

Cloud-Native Predictions for 2020
Two years ago, I wrote predictions about Kubernetes and was dead on, which obviously means I was completely motivated to write another one, entitled “ …

Production-grade Kubernetes Now in an Azure Region near You
We’re thrilled to announce that Giant Swarm is now available on Azure. This adds to the support we already have for AWS and on-premise installations a …

Cloud native predictions for 2025
Or better yet, listen to the Giant Conversations predictions episode here! Writing predictions is an interesting exercise (I've been doing this since …