by The Team @ Giant Swarm on Feb 1, 2021

At Giant Swarm, we live the DevOps life. This means we run what we build. The twist is that we manage it mostly for people in organizations outside of ours, though we pride ourselves on dogfooding too.
As the install base we are looking after grows and we manage more and more clusters, we are finding the value of silence, as in silencing alerts. Since it may come off as odd that a managed service company silences alerts, let me provide some context.
At the time of writing this post, Giant Swarm is close to 200 clusters on 25 installations. These clusters are used by different customers for different purposes. As such, not all of them need to be monitored closely all the time. Silencing would typically be for a limited amount of time and for specific use cases. In general, we were looking for a systematic way to control silences and manage their expiration, as applicable to the use case. Using a Custom Resource (CR) and having things in GitHub helps us keep track.
Before looking into developing something ourselves, we typically look upstream. Maybe someone in the community is looking to solve a similar need. A quick look at feature requests on the Prometheus Operator repo shows a request for creating alertmanager silences via CRD. The use cases given, there are:
- I am a cluster operator who needs to upgrade the etcd cluster. I want to create a silence prior to taking down each etcd node and remove the silence after I have finished upgrading the node.
- I am a developer who needs to update a StatefulSet. I want to create a silence for the duration of the StatefulSet change and remove it when the change is complete.
Let’s dive a little deeper into our use cases. Some general examples would be:
- Old cluster version with a bug
- Customer team testing admission webhooks and expects to kill cluster
- CI app on cluster exhausts K8s API and increases some of the metrics alert manager fire on
Example use case
A hypothetical setup would look like the diagram below:
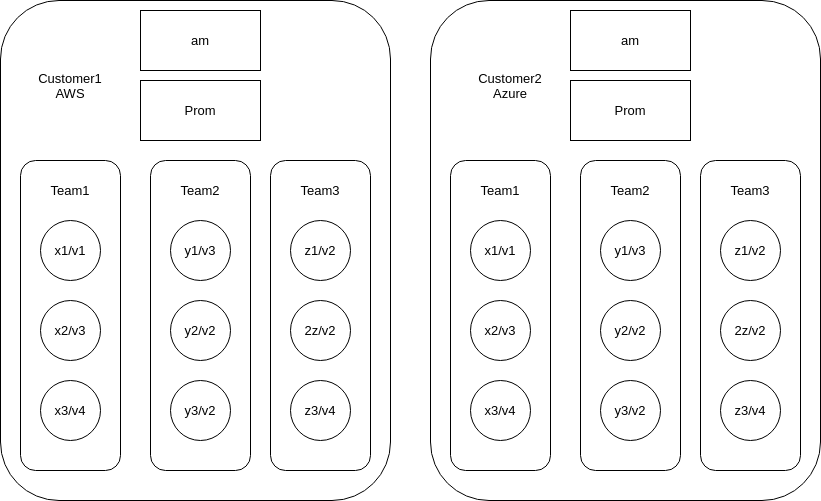
Some typical silences we would want to have:
- Mute all customer2/team2 clusters on v2
- Mute AWS clusters in v4
- Mute alert “ServiceLevelBurnRateTooHigh” (true story) on all v3 clusters
Now, take the diagram above and multiply it by ~100 (since we are currently running ~200 clusters) and that’s a whole lot of moving parts to keep track of.
The solution
The current solution we have created to manage alertmanager alerts is giantswarm/silence-operator.
The silence-operator monitors the Kubernetes API server for changes to Silence objects and ensures that the current Alertmanager alerts match these objects. The Operator reconciles the Silence Custom Resource Definition (CRD).
How it works
- The deployment runs the Kubernetes controller, which reconciles
SilenceCRs. - A Cronjob runs the synchronization of raw CRs definition from the specific folder, by matching tags.
A Sample CR
apiVersion: monitoring.giantswarm.io/v1alpha1
kind: Silence
metadata:
name: test-silence1
spec:
targetTags:
- name: installation
value: kind
- name: provider
value: local
matchers:
- name: cluster
value: test
isRegex: false
There is no expiration date. As long as the CR exists the alertmanager is silenced.
- The
targetTagsfield defines a list of tags, which thesynccommand uses to match CRs towards a specific environment.
To ensure the raw CR is stored in /folder/cr.yaml, run:
silence-operator sync --tag installation=kind --tag provider=local --dir /folder
- The
matchersfield corresponds to the Alertmanager alertmatchers
As mentioned above, we have very specific needs around silencing different alerts and managing the silencing history. Even if you don’t require syncing your git repo with silences into your Kubernetes clusters, you can use the operator with minimal CRs. See the example below:
apiVersion: monitoring.giantswarm.io/v1alpha1
kind: Silence
metadata:
name: test-silence
spec:
targetTags: []
matchers:
- name: cluster
value: test
isRegex: false
For more information about the operator, please visit the repo or contact us.
Bridging the gap: Kubernetes on VMware Cloud Director
While the general trend of the last decade has been to move workloads to the cloud, along with major companies jumping on the bandwagon to offer their …

Istio monitoring explained
Nobody would be surprised if I say “Service Mesh” is a trending topic in the tech community these days. One of the most active projects in this area i …

Manage Kubernetes Secrets using AWS Secrets Manager
Kubernetes has a built-in feature for secrets management called a Secret. The Secret object is convenient to use, but does not support storing or retr …