Application Configuration Management with Kpt
by Puja Abbassi on Jan 18, 2021
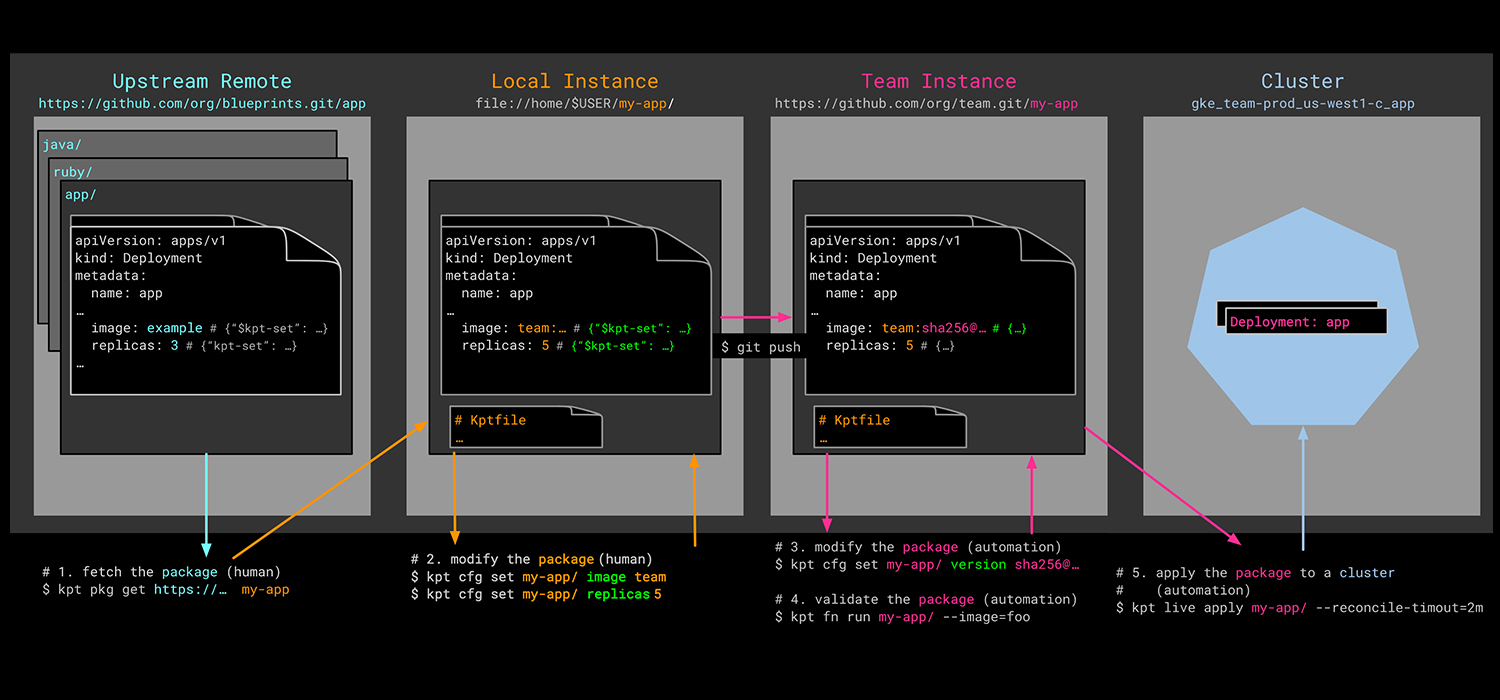
Through the course of this series on application configuration management in Kubernetes, we've looked into many of the popular approaches that exist in the ecosystem at this juncture. But, before we leave the topic, there's time for one final episode that discusses the merits of a new initiative fronted by Google. Kpt (pronounced kept) was announced at the end of March 2020 and is an opinionated approach to configuration management in Kubernetes.
Kpt is so-called as a play on the 'apt' package manager found in Debian-derived Linux distributions and has an assumed correlation with Kubernetes because it starts with a 'K'. Many of the tools we've considered in this series have steered away from describing themselves as package managers, perhaps in deference to the Helm project, but not so with Kpt. To provide a wider description, Kpt is a tool for building declarative workflows using Kubernetes resource configuration, but packages are a central component to the way that it does this. We'll discuss this in more depth in a while, but first, let's see why Kpt came to be.
Rationale
Kpt goes big on the principle that configuration should be handled as data rather than as code. This is the exact opposite route of travel espoused by other projects that rely on templating to transform configuration using Domain Specific Languages (DSLs). And also, for that matter, solutions that rely on high-level programming languages to achieve the same effect, such as Pulumi.
Kpt, then, assumes that it will receive raw configuration data (Kubernetes resource definitions) as input, and will write transformed configuration data as output, back to the same file location. The philosophy employed is much like the UNIX philosophy, where the output from one command can feed into another command as input. Think piping commands together on the Linux command line. Additionally, logic concerning Kubernetes resource types has specifically been excluded from Kpt's codebase, with the necessary domain knowledge being provided externally, using the OpenAPI resource schema provided by Kubernetes.
In adopting this approach, where raw configuration is read and written as input and output, Kpt ensures that it's not reliant on any other competing or complementary tool in the Kubernetes ecosystem. At the same time, however, it can work in conjunction with them if required. So, that's broadly the rationale behind Kpt, let's return to packaging.
Packaging
When we talk about packaging in the context of Kubernetes, we instantly think of Helm charts. Ultimately, however, Kubernetes application definitions boil down to a set of related Kubernetes resource manifests, that can be applied to a cluster to get your application up and running. These resource definitions (raw manifests, or packaged Helm charts) are often stored in a version control system (VCS); most commonly, git. This ensures there is a reliable 'single source of truth' for the configuration of the application at any point in time.
Kpt takes advantage of the 'single source of truth' notion and views a git directory containing Kubernetes resource definitions as a package. It uses a YAML file called a 'Kptfile' to describe the package. And, whilst it's straightforward to initiate a new package in a local directory, or turn an existing local directory into a package, Kpt also provides the means to retrieve or 'get' remote packages. This enables DevOps teams to work with third-party content, as well as corporate-owned assets.
Kpt uses the 'kpt' CLI for manipulating resource configuration data and has a series of sub-commands, including 'pkg'. Hence, a 'kpt pkg get' command with appropriate arguments will retrieve the contents of a remote repo or repo sub-directory. Executing a 'get' will produce a 'Kptfile' (if one doesn't already exist in the content) similar to that shown below:
apiVersion: kpt.dev/v1alpha1
kind: Kptfile
metadata:
name: my-app
upstream:
type: git
git:
commit: 9e827ca7d9f2ba7b2ccc4ddabe3d60df19c876a3
repo: https://github.com/acmeco/my-app
directory: /
ref: master
This new, local package will be linked to the repo for the entirety of its life, which means upstream updates can be merged into the local package as and when desired.
Any updates are performed using the 'kpt pkg update' command, and there are a few different merge strategies available for combining upstream changes into a local package. One strategy fails the update attempt if the local package has been modified, whilst another nukes any local changes and replaces its contents with the upstream content. A more subtle approach is to either compare and merge or to apply a git patch.
Configuring resources
One of the big challenges with application configuration is how to reconcile the need to provide a static package of resources, whilst allowing for its customization to suit a specific scenario. Most approaches elect to use templating to achieve this, but as we said right at the top of this article, Kpt has elected to shy away from this approach.
Instead, Kpt adopts an interesting approach to this problem - it uses the Kubernetes Open API resource schema to help package authors to define customizable configuration. It does this using 'setters' and 'substitutions'; the former provides configurable field values, and the latter provides substituting values into part of a field value. Perhaps it's easier to visualize with an example.
If we assume for a moment that a package author provides a Deployment resource for an application with the 'replicas' field set to '1'. But, she also wants to provide the package consumer a way of overriding this field value using the 'kpt' command line. To do this, the package author provides a comment in the resource definition, which references an OpenAPI setter defined in the 'Kptfile'. It might look like this:
apiVersion: apps/v1
kind: Deployment
<snip>
spec:
replicas: 1 # { "$ref": #/definitions/io.k8s.cli.setters.replicas" }
<snip>
The corresponding syntax in the 'Kptfile' would look like this:
apiVersion: kpt.dev/v1alpha1
kind: Kptfile
<snip>
openAPI:
definitions:
io.k8s.cli.setters.replicas:
description: Sane default value
x-k8s-cli:
setter:
name: replicas
value: "1"
setBy: Puja Abbassi
With its knowledge of the Kubernetes resource schema (which it retrieves from querying an API server using the current context), Kpt knows which resource configuration files scoped inside the package contain the configurable field:
$ kpt cfg list-setters ./
NAME VALUE SET BY DESCRIPTION COUNT
replicas 1 Puja Abbassi Sane default value 7
All the package consumer needs to do to customize the field value for the package, is issue another 'kpt cfg' command:
$ kpt cfg set ./ replicas 3
set 7 fields
Kpt updates the value of the 'replicas' field in the Deployment manifest, as well as updating the setter definition in the 'Kptfile' with the configured value. Substitutions work in a similar manner.
Applying resource configuration
Once you're finished tinkering with the configuration of the resources that describe your application, you'll want to apply them to a target Kubernetes cluster. Ordinarily, you'd use the 'kubectl apply' command to achieve this, but if you wanted to keep it in the Kpt 'family', you can.
Kpt uses the 'next generation' apply command that is being developed as part of the Kubernetes SIG CLI. In addition to applying resources to a cluster, it also provides for status reporting and the pruning of any resources associated with the deleted configuration. To aid the pruning process, Kpt's version of 'apply' requires a ConfigMap object to keep track of previously applied configuration objects. The 'kpt live init' command achieves this, with the resource definition created in a file called 'inventory-template.yaml' at the root of the package.
Advanced configuration with functions
What about logic for manipulating resource definitions, a feature often cited as being of paramount importance to DevOps teams managing application configuration? As we said earlier in this article, Kpt deliberately excludes any built-in types that reflect the Kubernetes domain, or any code that performs anything other than simple setting or substitution of values. A utility like 'sed' could perform the same functions, just without the higher-level concepts like packages, resource retrieval, applying configuration to a cluster, and so on. So, if this logic isn't built-in, does Kpt ignore this requirement altogether?
The answer is no. Kpt provides a mechanism for invoking purpose-built logic that can be applied to packaged resources, but the code is out-of-tree. Kpt uses a function invoker to spin up containers with logic inside, that can be used to do things like generate configuration, transform it, and even validate it. You might want to run some resource validation prior to committing changes, for example, to ensure resource labeling policy is adhered to. Kpt functions, which conform to a 'functions spec' and are designed to be chained together, are written using a Typescript-based SDK (although, technically, the logic can be written in any language). There's even a catalog of functions to get you started.
Conclusion
There's quite a bit that we haven't been able to cover in this article for brevity purposes. For example, Kpt uses the Blueprint concept for working with composable and reusable components of configuration. In conjunction with Kustomize, a Blueprint could define and separate configuration meant for change by Blueprint consumers and configuration that is designed to remain static. It's fairly plain to see that Kpt brings a comprehensive and opinionated approach to application configuration management. It could be used to supplant your existing method of configuration management entirely. Or, you could easily employ a subset of features and use it alongside other existing tools in the ecosystem.
Kpt has arrived on the scene just as the number of solutions trying to solve the same problem is multiplying. So, what are its chances of success? In part, that will be determined by whether DevOps teams perceive the opinionated workflow approach as an improvement over the existing approaches in the community. But, also, we need to consider that this tool comes from Google's stable and forms part of its popular set of container tools. In that respect, it carries a lot of weight and it's certainly one to watch.
You May Also Like
These Related Stories

Application Configuration Management with Helm
Following on from our introductory article on application configuration management in Kubernetes, this article looks at the topic from a Helm perspect …

Application Configuration Management with Kustomize
In this series of articles, we're taking an in-depth look at application configuration management in Kubernetes. In the previous article, we explored …

Application Configuration Management with Pulumi
As this series on application configuration management in Kubernetes has progressed, the predominant message that has emerged is the community's desir …